Trajectory Representation Learning Based on Road Network Partition for Similarity Computation
Trajectory Representation Learning Based on Road Network Partition for Similarity Computation
现有的轨迹表示学习工作要么使用网格对轨迹点进行聚类,要么需要道路网络类型等外部信息,这在查询精度和适用场景方面都不够好。
提出了一种新的基于分区的表示学习框架PT2vec,该框架利用底层道路段进行相似性计算,而不需要额外的信息。为了减少单词的数量并确保两个空间相似的轨迹在潜在特征空间中具有紧密的嵌入,我们将网络划分为多个子网络,每个子网络由一个单词表示。然后采用基于gru的seq2seq模型进行词嵌入,并设计了基于空间特征和拓扑约束的损失函数
贡献点
提出了一种道路网络约束轨迹表示学习框架,该框架利用底层道路进行相似性计算,不需要额外的信息。
提出了一种新的基于seq2seq的模型和基于PT-Gtree索引的高效相似度查询算法。
提出了一个考虑轨迹空间特征和路网拓扑约束的损失函数来学习轨迹的表示
问题定义
主要问题
给定一组路网约束的轨迹数据,我们的目标是为每条轨迹T学习一个表示v∈Rd (d为欧氏空间维数),使该表示能够反映轨迹相似度计算的空间特征和拓扑信息,其中相似度函数基于向量欧氏距离,可通过下式(1)计算。
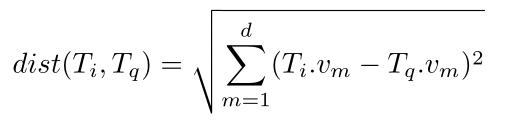
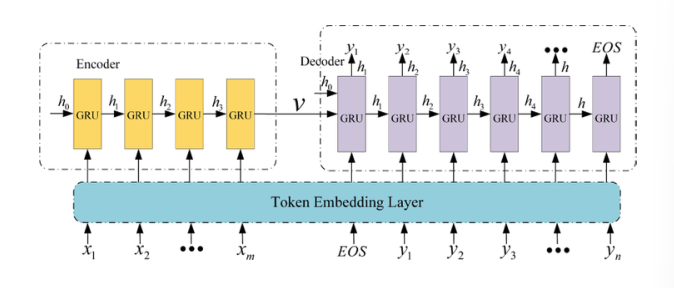
序列编码解码器
方法
框架
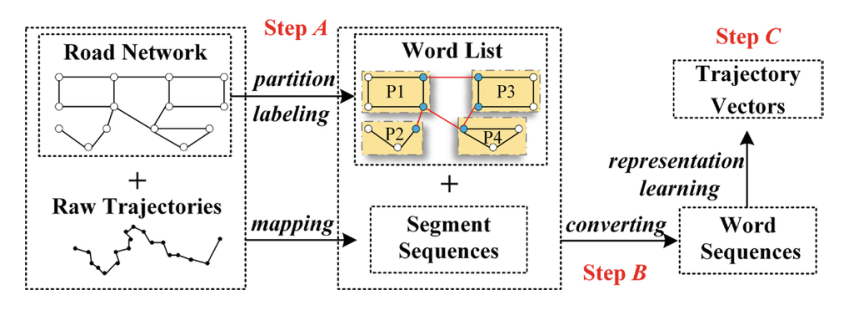
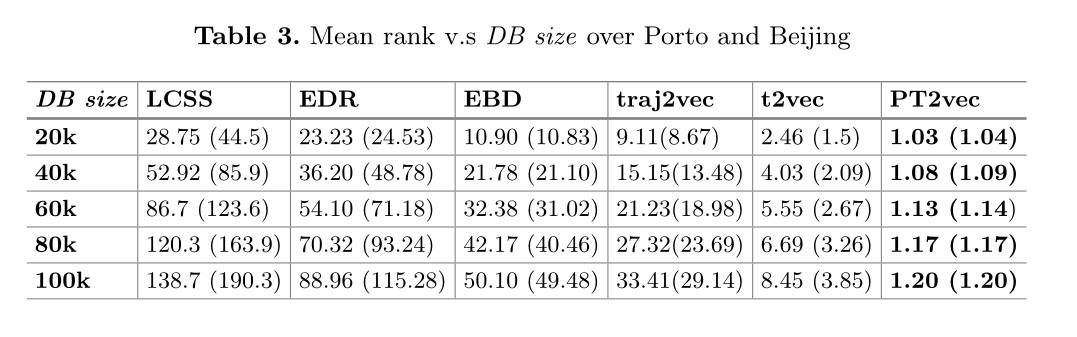
PT2vec利用底层道路段来解决低(不均匀)采样和原始轨迹中有噪声的采样点的问题。由于路网中的边缘数量往往很大,如果直接以边缘ID作为单词,训练时间会很长。为了减少词的数量,并确保两个空间相似的轨迹在潜在特征空间中有紧密的嵌入,我们将整个路网在空间上划分为多个大小相等的子分区,每个子分区以及每个边界边缘都用一个词表示(步骤a)。
为了获得轨迹(词)序列,首先将每个原始轨迹作为道路边缘序列映射到道路网络上(步骤B),这里可以使用任何地图匹配方法。然后,根据轨迹所遍历的子分区和所定义的词,生成用于词嵌入的轨迹序列。
PT2vec采用基于gru的序列编码器-解码器模型来学习轨迹的表示(步骤C),损失函数同时考虑了空间特征和拓扑信息。因此,不同长度的轨迹可以表示为等长度的向量。
路网分区
分区方法
基于分区的词定义方法,将整个网络递归划分为多个大小相同的子分区,每个子分区用一个词表示。这样,同一子分区中的边在空间上是接近的,使用相同的词可以保证它们在向量空间上也是接近的。连接不同子分区的边界边也被视为一个词,因此可以保留原有的拓扑信息。
原路网中某条边的两个端点位于不同的子分区,则该边不属于任何子分区。这样的边称为边界边,它连接不同的子分区。
采用了[6]多级划分算法,这是一种著名的启发式算法,在之前的许多作品中都使用过[8,19,27]。它首先通过对顶点和边进行粗化来减小网络的大小,然后使用传统的网络划分算法(如Kernighan-Lin算法)对粗化后的图进行划分。最后,对子网络进行粗化,生成原始网络的最终分区。因此,该算法可以保证每个子网的大小几乎相同。
词列表生成
按顺序对子分区和边界边缘进行编号,这些标签就是相应的单词。
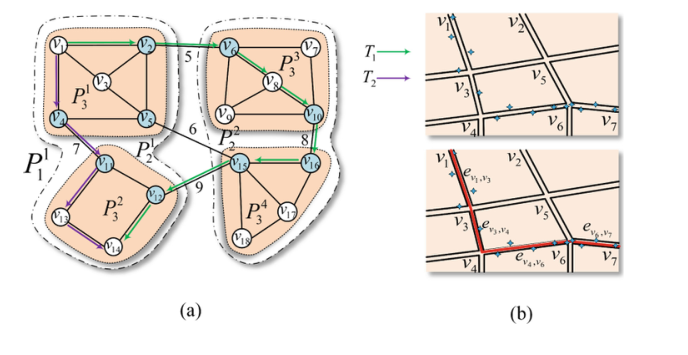
从原始轨迹到词序列
T2是{1,7,2}。同样,T1的单词序列为{1,5,3,8,4,9,2}。
轨迹表示学习
采用基于rnn的编码器-解码器模型处理文本序列任务,该模型不能捕捉轨迹中的空间特征,也不能考虑轨迹底层道路网络的拓扑结构。为了解决这些问题,我们提出了一个基于空间和拓扑的损失函数来优化目标。
现有损失函数
最大化输出序列的联合概率
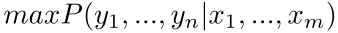
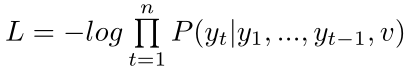
基于空间和拓扑的损失函数
只对目标词周围的少数重要词分配概率,既考虑了距离和拓扑关系,又减少了概率计算量,从而提高了学习效率和效果。
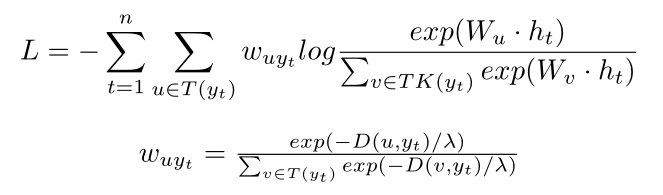
轨迹相似度查询
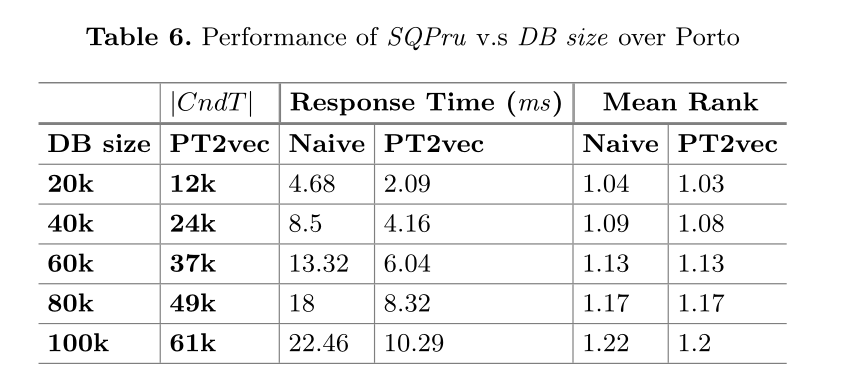
轨迹用PT2vec表示为等长向量,因此相似性查询只需要比较这些向量与查询向量之间的欧氏距离。具体来说,当给定查询轨迹时,首先使用PT2vec模型将其表示为向量。然后计算查询向量与数据库中每个向量之间的欧氏距离,并返回最接近的轨迹。时间复杂度为O(n + |v|),其中|v|是向量的长度。为了进一步提高查询效率,我们利用剪枝思想过滤掉空间中离查询轨迹较远的轨迹。特别地,我们提出了一个层次树索引结构PT-Gtree,并将轨迹存储到树节点中。
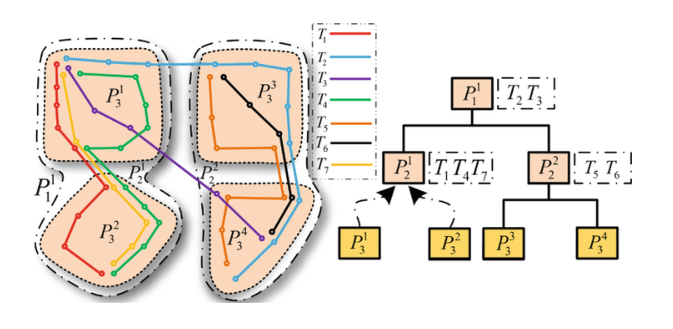
基于分区的轨迹索引,PT-Gtree
回到路网划分方法。如果我们保留递归过程生成的每一层分区,我们可以以自顶向下的方式为轨迹索引构建分层树结构
根节点是整个路网。叶节点是用于生成单词的子分区,非叶节点是分区过程的中间结果(子分区)。路网中相似度高的轨迹在空间上是相邻的
相似查询算法,SQPru
相似度查询优化算法SQPru采用filter - refine机制进行相似度查询。设TS为轨迹集,Tq为查询轨迹。SQPru过滤掉那些与Tq相似度较低的轨迹,只精确计算(精炼)候选轨迹之间的欧氏距离。

实验
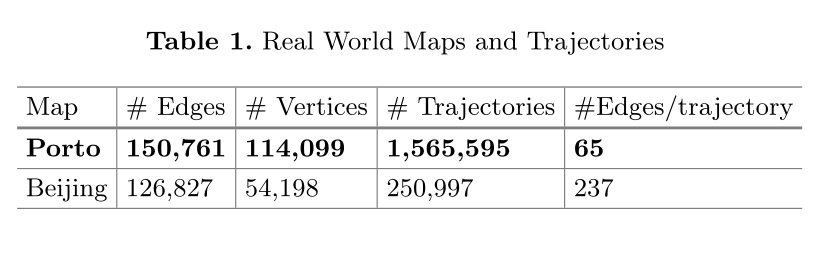
数据集
查询
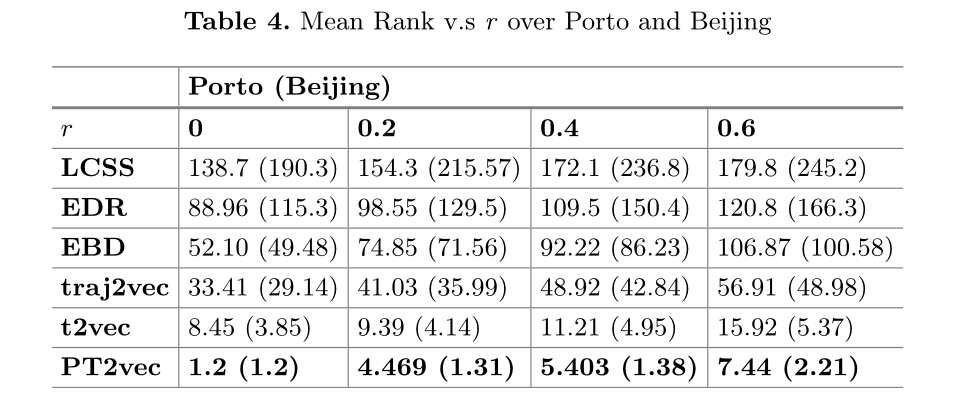
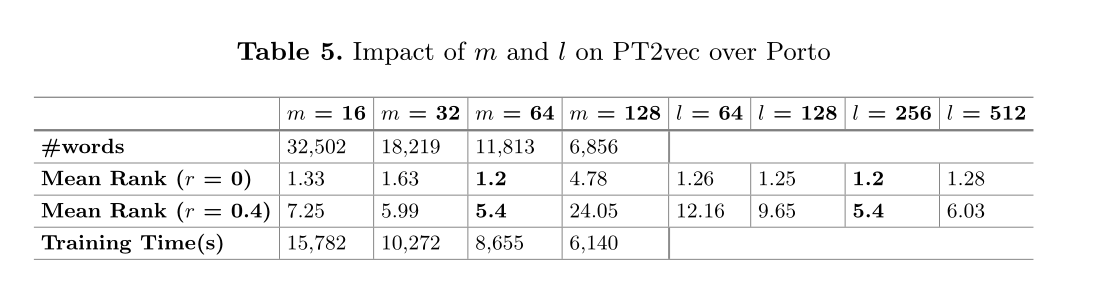
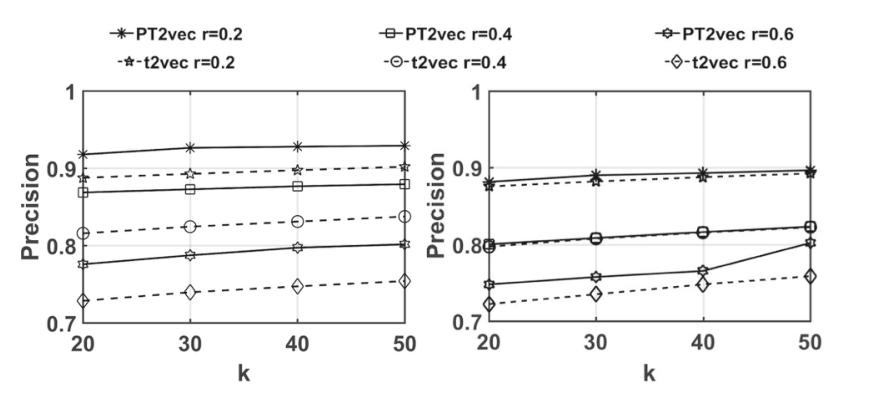
1)最相似轨迹查询。对于每个查询轨迹Ta,我们使用欧几里得距离从目标数据库中找到最相似的轨迹Ta。2) k-NN查询。我们使用t2vec和PT2vec从目标数据库中找到每个查询轨迹的k-NN轨迹作为ground truth。
实验结果