
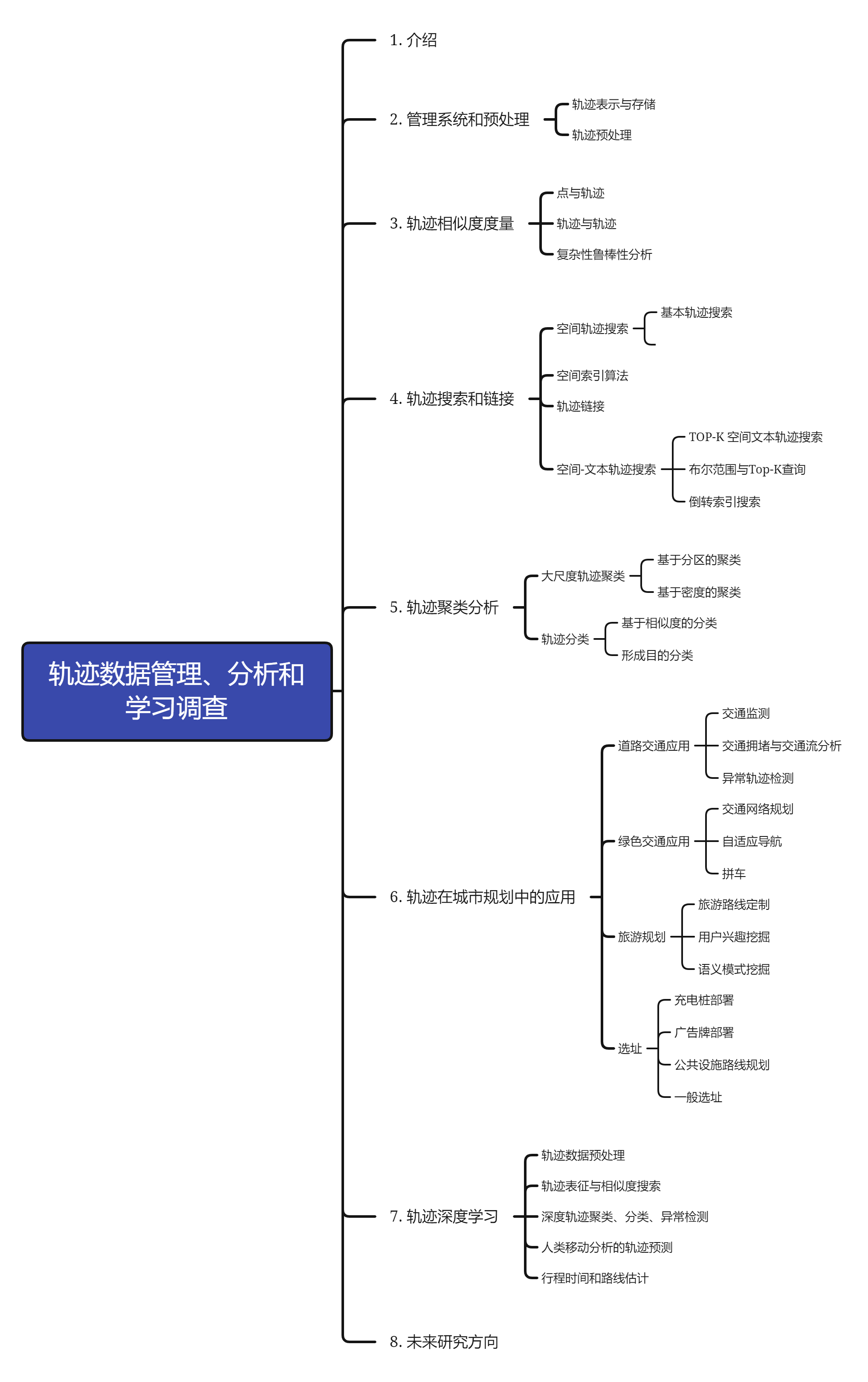
轨迹数据管理、分析和学习调查
.介绍
轨迹数据
附加信息γ可以包含在基于位置服务生成的轨迹T中的每个点p上例如,文本数据可以整合到社交网络签到数据或旅行博客的轨迹中,并被称为空间-文本轨迹[19,87]、语义轨迹[193]或符号轨迹[73]。
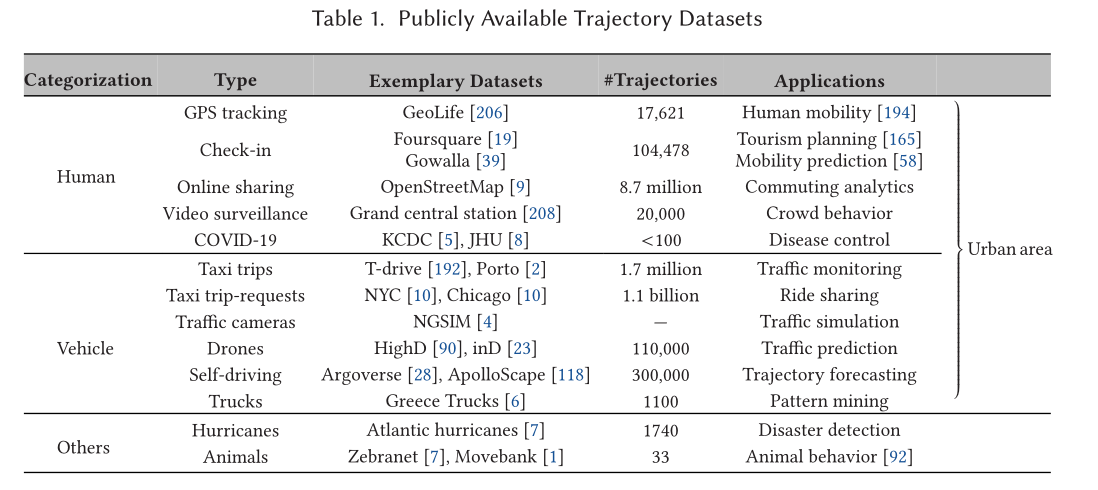
公共轨迹数据集:人类、车辆(汽车、卡车、火车、公共汽车、有轨电车等)、其他
轨迹数据收集、管理、代表性应用和广泛使用的深度学习模型
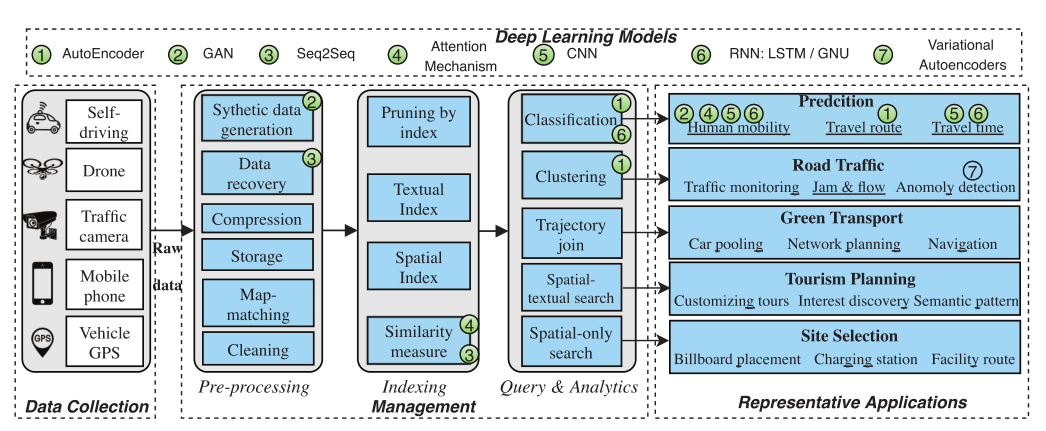
数据管理和分析系统有几个基本组成部分:
- 数据清洗
- 数据存储
- 相似性度量
- 索引化
- 查询和分析
- 下游任务与应用
调查内容:
- 可伸缩性与数据存储
- 处理流水线分解
- 代表性应用
- 深度轨迹学习
- 未来轨迹数据管理挑战展望
2. 管理系统和预处理
2.1 轨迹表示与存储
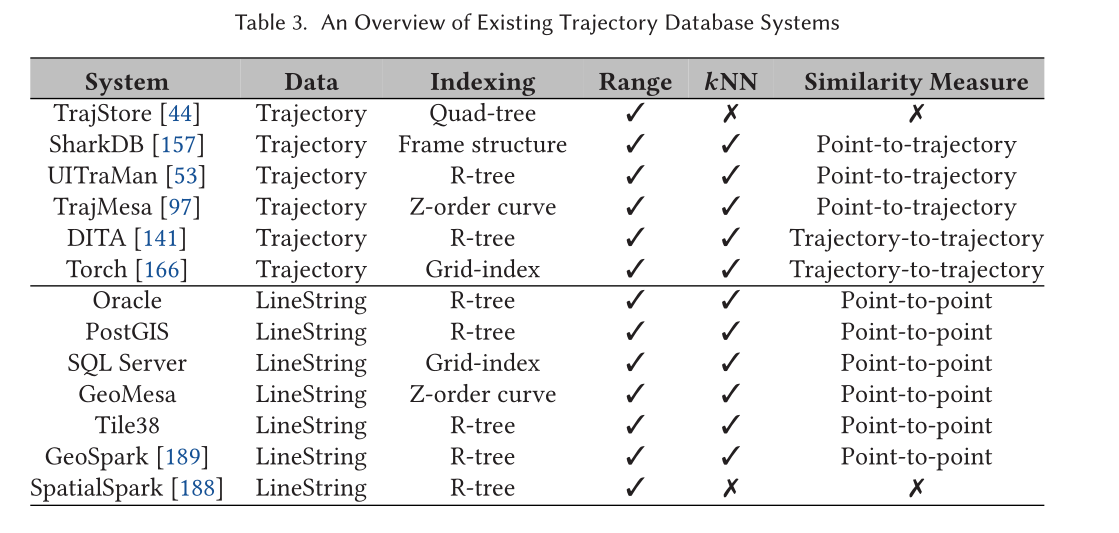
2.2 轨迹预处理
轨迹清洗
数据分割[26]、校准[147]和丰富[13]是轨迹数据最常用的三种清洗技术
轨迹压缩
现有的轨迹压缩技术可分为基于简化的和基于路网的两类。剔除多余点是采样率较高时常用的空间约简方法,通常称为轨迹化简
可以使用道路网络来实现更好的压缩
字符串压缩技术[184]可以直接用于轨迹数据,并且使用这些技术也可以简单地存储任何时间信息。
路网匹配
利用道路网络,地图匹配[114,124]将原始轨迹投射到真实路径上,并支持清洗和压缩
三种生成 ground truth 的方法:(1)在道路上使用配备GPS设备的真实车辆[124],(2)人工判断[114],(3)模拟GPS采样[83]
3. 轨迹相似度度量

3.1 点与轨迹
最佳连接轨迹(kBCT)搜索[38,131,149]可以说是最常用的点到轨迹相似性搜索公式
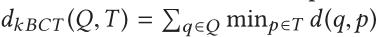
对所有最近邻居对之间的距离求和的替代方法是另一种著名的度量方法,称为最近对距离(CPD)
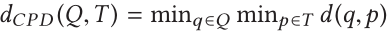
3.2 轨迹与轨迹
3.2.1 点度量
最常用的相似性度量大致分为五类:基于曲线的、真实距离的、编辑距离的、时间感知的和基于段的
Hausdorff距离[134]是度量空间的两个子集之间的对立分离
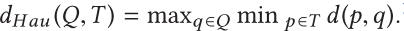
离散Fréchet距离(DFD)扩展Hausdorff距离,以考虑曲线上点的位置和顺序
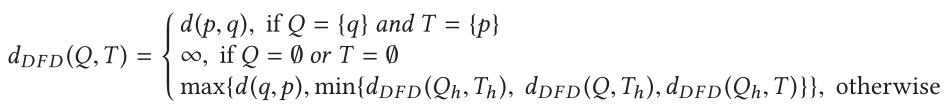
轨迹数据的时间序列测量包括动态时间扭曲(DTW),最长公共子序列(LCSS),实序列的编辑距离(EDR),实惩罚的编辑距离(ERP)
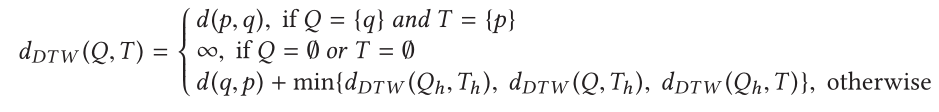
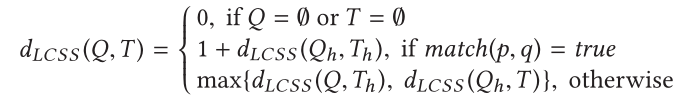
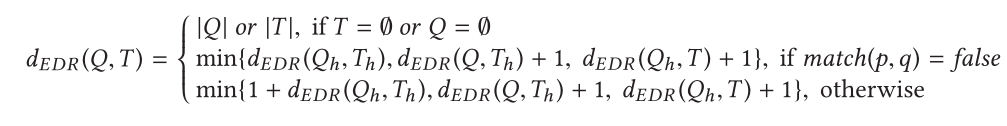

3.2.2 时间感知点相似性
除了空间信息外,时间信息也是精确采样率校准的重要因素。
一种叫做DISSIM的方法来计算不相似度
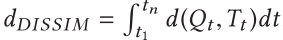
3.2.3 基于轨迹段的相似性
另一种方法是将轨迹转换为分段。这种方法已被证明可以减少样本不匹配的影响,以及降低应用的相似性计算的复杂性。
最长重叠路段(LORS)该度量受到LCSS的启发,并适应于利用映射匹配数据的固有属性。LORS不计算点之间的欧几里得距离,以确定它们是否遵守阈值距离约束。相反,首先识别出轨迹之间的重叠部分,然后重用来计算相似度。
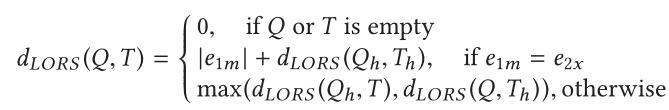
LCRS可以定义为
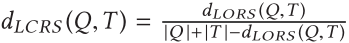
基于边缘的距离(EBD)
dEBD (Q,T) = max(|Q|, |T |)−|Q∩T |
3.3 复杂性和鲁棒性

4. 轨迹搜索和链接
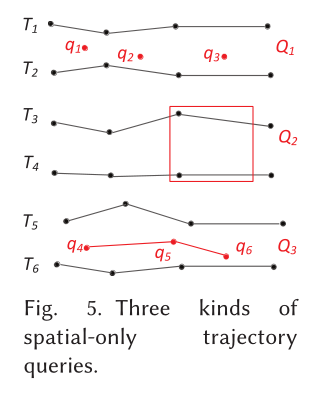
4.1 空间轨迹搜索
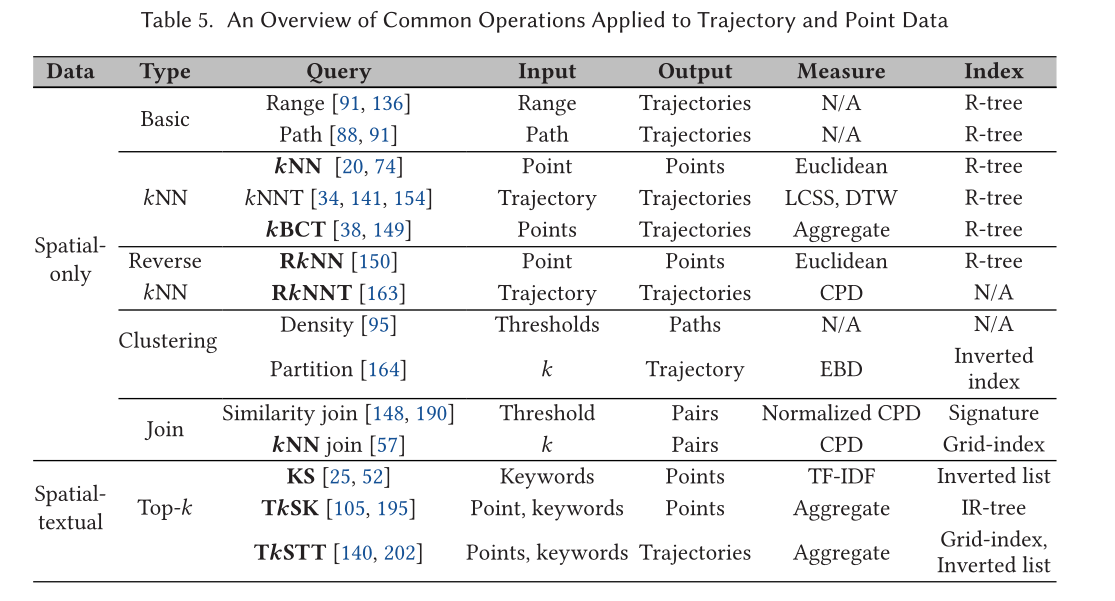
通过输入、输出、相似度度量和最合适的索引,比较和对比几种常见的轨迹查询。
4.1.1 基本轨迹搜索
基本轨迹搜索包括三个经典的查询公式。
最基本的是范围查询(RQ),它查找位于空间或时间区域的所有(子)轨迹。范围查询在交通监控中有很多应用,例如返回十字路口的所有车辆。
第二个是路径查询(PQ),它检索包含给定路径查询的任何边的轨迹。
第三种是严格路径查询(SPQ),它可以找到从头到尾遍历整个路径的所有轨迹。
定义5(范围查询)。给定一个轨迹数据库$D = {T1,…,T|D |}$和查询矩形区域Qr,范围查询检索轨迹:$RQ(Qr) = {T∈D|∃pi∈T (pi∈Qr)}$。
定义6(路径查询)。给定G中的路径Qp,路径查询检索通过Qp的至少一条边ej的轨迹T: $pq (Qp) = {T∈D|∃ei∈T, ej∈Qp (ei = ej)}$。
定义7(严格路径查询)。给定一个Qp,严格路径查询检索的轨迹的边都可以在$Qp: SPQ(Qp) = {T∈D|∃i, j(Tij = Qp)}, Tij = {ei, ei+1,…, ej}$为T的子轨迹。
4.1.2 K近邻查询
k近邻查询是在空间数据库中广泛应用的一种查询方法,用于从大量的对象中找到与给定查询对象相关的子集
定义8 (k轨迹上最近邻查询)。给定一个轨迹数据库$D = {T1,…,T|D |}$和查询$Q = {q1,q2,…,q | q |}$, k个最近邻查询(kNN(q))检索一个$set Ds⊆D$,具有k个轨迹,使$∀T∈Ds,∀T’∈D−Ds, D (Q,T) < D (Q,T’)$
查询轨迹
给定一个查询轨迹Q, k个最近邻轨迹查询的目标是根据给定的轨迹相似度度量,找到k个与Q最相似/最接近的轨迹
查询点
4.1.3 反向K近邻查询
给定一组点(或轨迹)D和一个查询点(或轨迹)Q, RkNN(Q)检索所有以Q为kNN的对象T∈D,即∀T, Q∈kNN(T)。
RkNN
RkNN查询旨在识别所有(空间)对象,这些对象的查询位置是k个最近的邻居。RkNN查询的重要应用包括资源分配和基于配置文件的营销.
反向轨迹搜索
给定一个轨迹数据集DT和一组路径DR(也定义为轨迹)和一个候选点集$Q = (o1,o2,…,om)$作为查询,RkNNT返回DT中使用点到轨迹相似性度量将Q作为k个最近路径的所有轨迹。RkNNT的主要应用是估计一条新总线路线的容量,并可以进一步用于规划一条源和目的地之间容量最大的路线
4.2 空间索引算法
在与轨迹相关的搜索问题中,为了提高效率,轨迹索引被广泛应用。轨迹数据离线处理,以提高可扩展性和精简搜索空间。现有的轨迹索引方法有两个组成部分:可索引点数据和映射表。
点索引
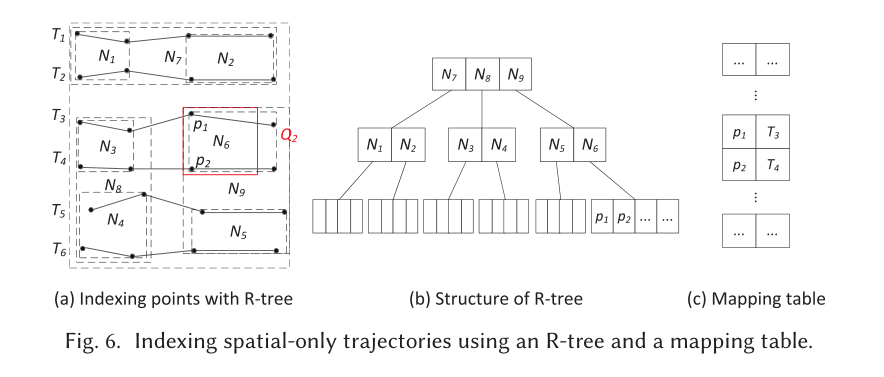
映射表
映射表用于将点映射到轨迹。在搜索到一个点之后,映射表识别出包含这个点的轨迹。
修剪机制
对于范围查询,大多数现有方法采用基于MBR的修剪,因为MBR与查询轨迹的交集可以有效地修剪搜索空间。如果节点与查询范围相交,则覆盖的对象可以从考虑中删除。
4.3 轨迹链接
给定两组轨迹S1和S2,以及一个相似阈值ε(或kNN搜索中的k),轨迹连接操作将返回S1和S2中所有相似度超过ε(或Ti∈kNN(Tj))的轨迹Ti和Tj。轨迹连接的主要应用是轨迹数据清洗、近重复检测和拼车。
分布式轨迹相似连接
由于距离计算的计算成本较高,通常采用分布式计算来解决轨迹连接问题。
4.4 空间-文本轨迹搜索
空间文本轨迹搜索将文本和关键字合并到数据中,相关轨迹具有多个必须考虑的相似度维度。
4.4.1 TOP-K 空间-文本轨迹搜索
相似性度量
与仅采用空间相似性度量相比,活动轨迹的空间文本度量同时依赖于空间和文本成分。两种不同相似性度量的线性组合是空间文本数据的常见解决方案。空间距离与文本的TF·IDF相似度相结合,在两者之间使用用户定义的权重,以基于目标应用程序来平衡重要性。
关键字点搜索
4.4.2 布尔范围和Top-k查询
布尔范围查询轨迹,并考虑空间,时间和文本信息,基于八叉树和倒排索引的索引来回答他们提出的查询。
4.4.3 倒转索引搜索
倒排索引被广泛用于有效地管理空间文本问题的文本信息
5. 轨迹聚类与分类
5.1 聚类大尺度轨迹
聚类相似轨迹以生成具有代表性的样本可以成为跟踪车辆和人类移动性的强大可视化工具
5.1.1 基于分区的聚类
给定一组轨迹,基于分区的聚类将轨迹划分为有限数量(k)的组(集群)。
5.1.2 基于密度的聚类
基于密度的轨迹聚类首先找到密集的“段”,然后将这些“段”连接起来生成具有代表性的路线。然而,最合适的方法来识别密集段高度依赖于数据的属性。
5.2 轨迹分类
对于城市数据,主要有两类轨迹分类问题:
(1)基于相似性的分类
(2)交通方式和活动分类
5.2.1 基于相似度的一般分类
与轨迹聚类的主要区别是,分类根据单个轨迹的特征为其分配标签,而聚类是对数据集中的所有项目进行的。
5.2.2 行程目的分类
推断旅行的目的对改善城市规划和治理有潜在的应用价值[161],但通常是通过人工调查来进行的。
6. 轨迹在城市规划中的应用
6.1 道路交通应用
6.1.1 交通监测
由于轨迹记录了道路上车辆的轨迹,因此开发了许多可视化系统[35]来观察和监控基于轨迹数据的过去或实时交通趋势和运动模式。用户可以交互式地探索特定区域或道路的交通状况,并在必要时进一步控制交通。
6.1.2 交通拥堵和交通流分析
实时交通监控使分析师能够实时跟踪特定道路或区域的使用情况,并可用于识别交通堵塞,通过数字交通标志或GPS应用程序通知通勤者。
交通流分析不依赖于限速等特定领域的特征,而不是通过检查单个路段来识别交通堵塞。目标是发现驾驶员的重要运动模式,例如重复使用由几个不同路段组成的共同路线。
6.1.3 异常轨迹检测
数据集中的异常轨迹或离群轨迹可以定义为位于整个集合分布的预定义置信区间之外的轨迹。它已被应用于识别人群中的犯罪行为和出租车司机欺诈检测等应用。相似性和聚类的结合可以用来解决这个问题。计算轨迹之间的相似性可用于识别数据集中最不相似的轨迹,而聚类可用于聚合可能不容易识别的常见趋势。
6.2 绿色交通应用
地铁、公交线路和加油站等公共交通网络为绿色通勤提供了更多的选择。轨迹数据通常应用于绿色交通(也称为“可持续交通”)应用中,用于优化网络设计、进行个性化和自适应导航以及拼车。
6.2.1 交通网络规划
通过挖掘出租车数据,首先聚类出租车轨迹上的所有点,以确定可能是公交站点的“热点”,然后根据两个站点之间的连通性创建公交路线,从而逼近夜间公交路线规划。
6.2.2 自适应导航
基于旅行距离的源目的地最短路径搜索在导航服务中得到了广泛的应用。该方法可以自适应地应用驾驶员的历史轨迹数据。通过精确的地图匹配技术,发现数据中的轨迹路径可以丰富路网模型,如每条道路的动态时间成本、驾驶员偏好。使用每个路段的动态旅行时间成本,旅行时间估计和最快路径搜索更加现实,捕捉各种交通状况。
6.2.3 拼车
有两种常见的方法来解决严重依赖轨迹数据的拼车问题。第一个是根据乘客和司机的历史轨迹数据对他们进行分组。基本目标是保持所有车辆的所有座位都被占用,本质上是一种箱子包装问题。另一种方法是仅使用乘客轨迹来检测频繁路线。
6.3 旅游规划
6.3.1 定制旅游路线
6.3.2 用户兴趣挖掘
通过利用语义信息和人类交互发现更多有用的模式。兴趣发现是一种有价值的工具,可以提高向游客推荐餐馆、景点或公共活动的有效性。利用轨迹数据进行旅游兴趣发现的三个最常见类别是(1)POI,(2)兴趣区域(ROI),(3)互动发现
6.3.3 语义模式挖掘
语义模式挖掘的目的是挖掘带有描述性文本信息的频繁移动,它比纯空间路径更全面。
6.4 选址
轨迹驱动选址作为一种核心决策工具,已成为提高企业利润和公共服务质量的关键因素。利用收集到的轨迹数据来估计所选地点对司机或乘客的影响,可应用于充电站放置、广告牌放置和设施路线设计等问题。

6.4.1 充电桩部署
随着电动汽车的日益普及,建造更多的充电站已成为一个关键问题。轨迹驱动充电站的部署旨在减少充电所需的绕行距离。
6.4.2 广告牌部署
广告牌投放的目的是找到数量有限的广告牌,最大限度地发挥对乘客的影响力,进一步增加利润。
6.4.3 公共设施路线规划
与逐点候选集选择不同,设施集还可以是覆盖多个候选的路线,例如规划自行车道和路线搜索。
6.4.4 一般选址
有几个一般的选址研究,不受任何一种情况的限制。与其设置成本预算,不如设置参数k从候选设备集中选择一组设备。
7. 轨迹深度学习
7.1 轨迹预处理
轨迹数据生成
生成合成而真实的位置轨迹在轨迹数据的隐私意识分析中起着重要作用。基于一组训练轨迹,提出了生成模型来生成轨迹
轨迹数据恢复
由于许多轨迹是在低采样率下记录的,低采样的轨迹不能捕获物体的正确路线。
7.2 轨迹表征与相似度搜索
轨迹表示学习的目的是将轨迹表示为固定维数的向量。然后根据矢量表示的欧氏距离计算两条轨迹的相似度,将相似度计算的复杂度从O (n2)降低到O (n)
基于学习表示的轨迹相似性对于不均匀、低采样率和有噪声的样本点具有鲁棒性。
7.3 深度轨迹聚类、分类和异常检测
7.4 人类移动分析的轨迹预测
RNN被广泛用于轨迹预测,除了时空上下文之外,大多数研究还从轨迹中学习用户表示来捕获用户偏好。
7.5 行程时间和路线估计
8. 未来研究方向及有待解决的问题
- 数据清洗
- 轨迹数据存储库
- 数据集成和运营商支持
- 性能基准测试
- 参数化
- 深度轨迹学习
- 无人驾驶轨迹
- 公共卫生的轨迹分析
