
GETNext:用于下一个POI推荐的轨迹流图增强Transformer
GETNext:用于下一个POI推荐的轨迹流图增强Transformer
Abstract
提出了一个不确定用户的全局轨迹流程图和一个新的图增强Transformer模型(GETNext),以更好地利用广泛的协同信息,更准确地预测下一个POI,同时缓解冷启动问题。GETNext将全局转换模式、用户的一般偏好、时空上下文和具有时间感知能力的类别嵌入集成到一个Transformer模型中,以预测用户将来的移动。
1. Introduction
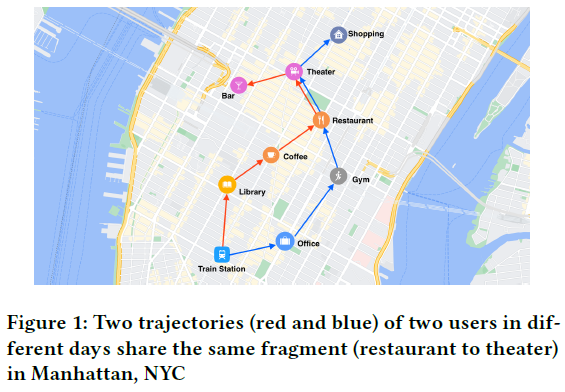
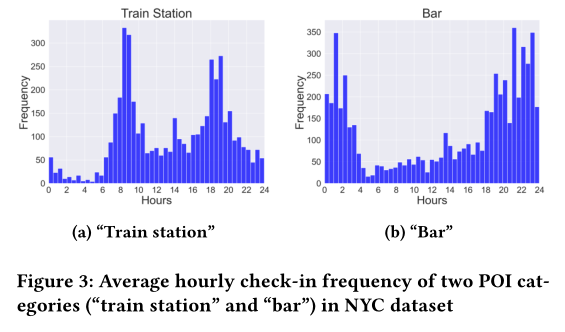
2. Problem formulation
用户集: $U = {u_1, u_2, … , u_M}$
POIs集: $P = {p_1, p_2, … , p_N}$
时间戳集: $T = {t_1, t_2, … , t_K}$
POI属性集: $p =
Check-ins: $q =
单个用户签到序列: $Q_u=(q^1_u, q^2_u, q^3_u…)$
所有用户签到序列: $QU={Q{u1}, Q{u2}, … ,Q{u_M}}$
将$Q_u$分割为$i$个$S^i_u$
POI推荐的目标是:给定{ $S^i_u$ }和某一用户的当前轨迹序列$S’=(q_1, q_2, … ,q_m)$来预测用户最可能访问的下一个POI
3. Model
3.1 Overview
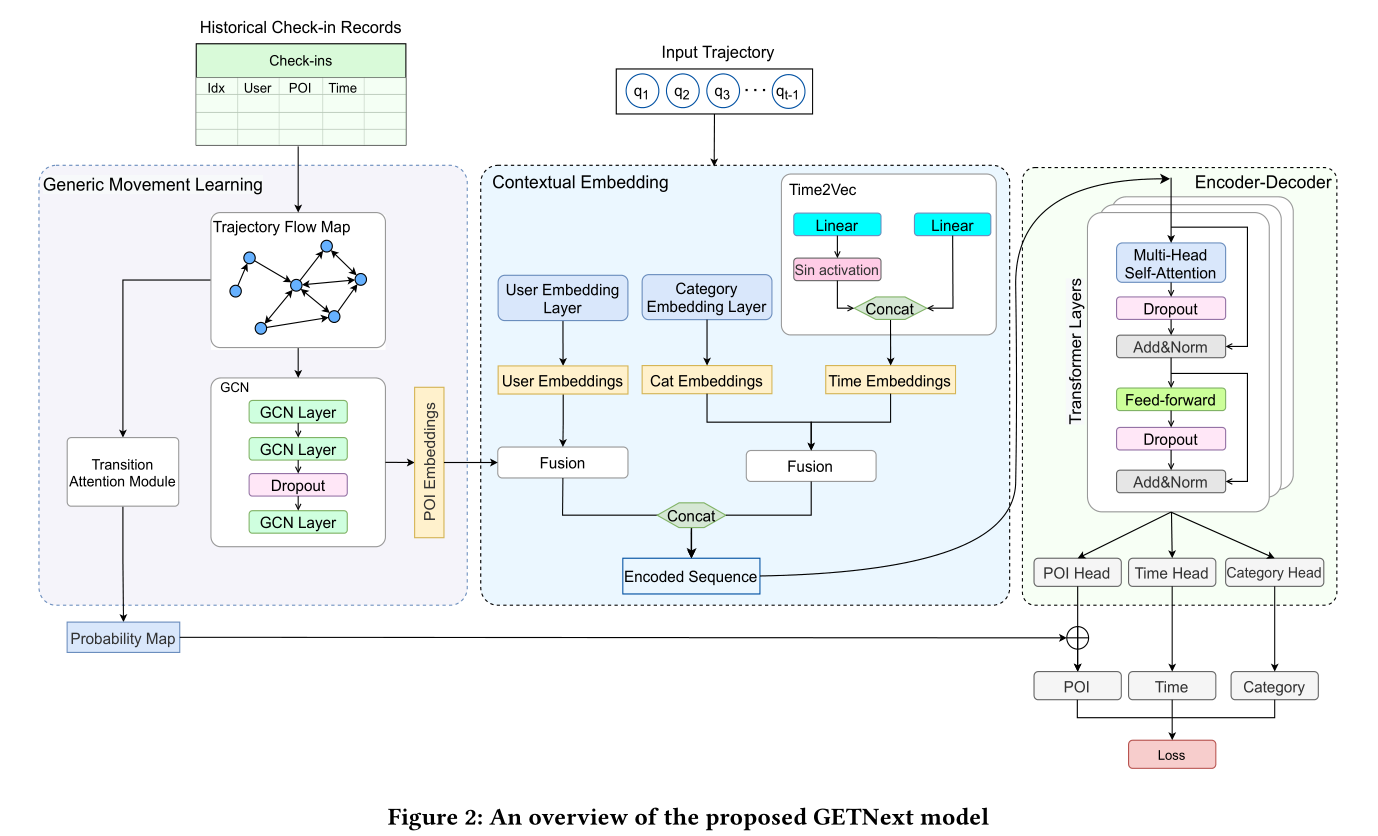
首先,定义了总结历史轨迹的轨迹流程图(见第3.2节)轨迹流程图通过两种方式影响推荐输出:
- 图神经网络(GNN)在轨迹流图上进行训练,生成POI嵌入,在每个POI上编码用户的通用移动模式,同时结合POI的类别、位置和签到频率。
- 注意模块以轨迹流图和节点特征的邻接矩阵为输入,生成转移注意图,建模poi之间的转移概率
然后,我们定义几个上下文模块来获得用户嵌入、POI类别嵌入和时间编码(通过time2vector模型):
- 将相应轨迹中的用户嵌入和POI嵌入结合起来以实现更好的个性化
- 将POI类别嵌入和时间编码结合起来来捕获用户对不同POI类别的时间偏好(例如,考虑高峰时间的火车站)
通过在签到记录中统一用户、POI类别、时间戳和POI信息,可以生成单个签入嵌入向量。然后可以将每个轨迹编码为这样的签入嵌入列表。然后我们使用一个Transformer编码器和多层感知器(MLP)头来产生一个POI预测。最后,利用学习到的带有残差连接的过渡注意图对预测POI进行调整。
3.2 Learning with Trajectory Flow Map
3.2.1 POI Embedding
轨迹流图的定义:给定S = { $S^i_u$ }构造一个有属性的加权有向图$G=(V, E, l, w)$
- 点集为POI集 $V=P$
- $l$ 为每个POI的属性
- 边为用户的访问路径
- 权重为重复的访问路径边的次数
给定轨迹流程图G,使用了图卷积网络(GCN)学习对常见POI转换模式和POI属性进行编码的POI向量化表示。
首先计算归一化拉普拉斯矩阵:
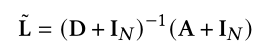
将GCN层之间的传播规则定义为:
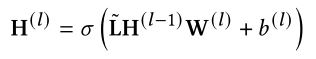
σ为leakyReLU激活函数
从空间的角度来看,在每次迭代中,GCN层通过将节点的邻居信息与节点自己的嵌入信息聚合在一起来更新节点的嵌入。Dropout在最后一层之前使用。
GCN模块的输出可以写成:
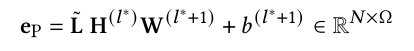
每个POI embedding表示了p点的带有所有用户轨迹中捕获的一般移动模式的位置信息,用于输入到下面的Transformer中
3.2.2 Transition Attention Map
转移注意图,放大了集体信息的影响,以显式模拟从一个POI到另一个POI的转移概率
给定输入G,注意转移图有如下公式进行计算:
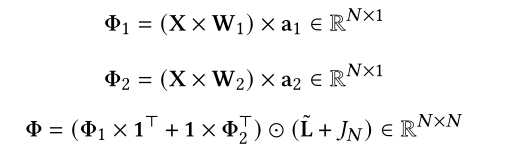
$W_1, W_2$ 是两个可训练的特征转移矩阵
$a_1, a_2$ 是用来构建注意力矩阵的两个学习向量
转移注意图$Φ$的行表示从一个POI移动到每个POI的(非归一化)概率,给定当前轨迹中的最后一个POI,我们查找Φ对应行中存储的转移概率,并使用这些概率调整后一个Transformer模块产生的推荐结果。
3.3 Contextual Embedding Module
3.3.1 POI-User Embeddings Fusion
为了捕获每一个用户的一般行为,训练一个嵌入层,将每个用户投射到一个低维向量上。每个用户的嵌入是从他/她的历史签到序列中学习的。
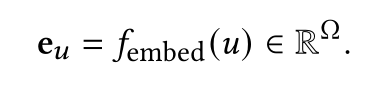
将POI嵌入和用户嵌入连接起来:

3.3.2 Time-Category Embeddings Fusion
本文探索的是POI类别的时间模式,而不是单个POI的。
首先采用time2vector对POI类别和时间进行编码。具体来说,将一天中的24小时分成48个时间段,每个时间段30分钟。我们将一个(标量)时间值投射到其中一个时间片。
时间片embedding:
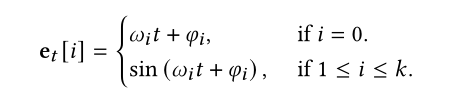
POI类别embedding:
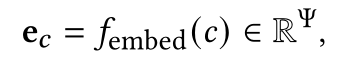
将两者融合:

得到本模块最终的嵌入:
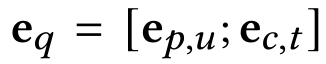
3.4 Transformer Encoder and MLP Decoders
3.4.1 Transformer Encoder
本部分采用只跟随几个MLP头的Transformer编码器。首先对每个历史签入进行签入嵌入,然后将这些签入嵌入叠加,形成第一个编码器层的输入张量$Χ^{[l]}$。
在 $l$ 层,输入 $Χ^{[l]}$ 首先是由一个多头自注意模块转换,第一注意力头,输出为:

合并来自不同注意空间的表征:
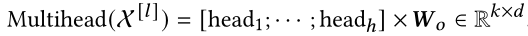
将层范数和残差连接应用于注意模块。注意模块的最终输出可以写成:
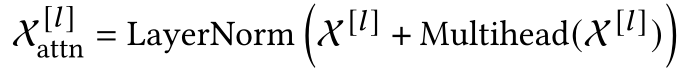
在每个编码器层中,在注意模型之后附加一个全连接(FC)网络。表示多头注意的输出:
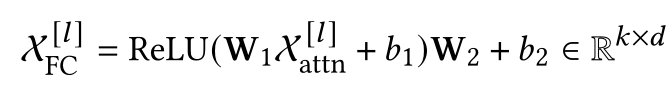
第i层编码器的输出为:
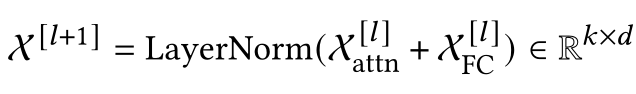
3.4.2 MLP Decoders
用多层感知器(MLP)解码器替换了Transformer解码器,并使用三个MLP头分别预测下一个POI、访问时间和POI类别。
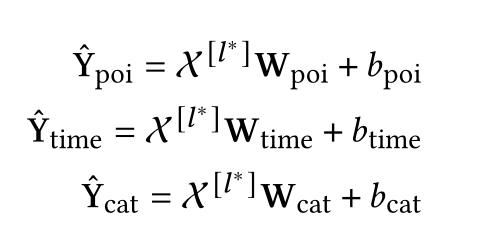
将得到的结果与转移注意图结合起来,得到最终结果:

除了POI头,我们还添加了时间头和类别头。我们根据POI预测下一次签入时间的主要原因如下:两次签入之间的时间间隔波动很大(例如,从半小时到长达6小时)。这是合理的,因为用户在不同的poi中花费的时间不相等,或者忘记记录某些签入。然而,这种波动对预测有相当大的影响。事实上,用户应该在下午5点收到关于下一个小时和下一个5小时的不同建议。因此,我们推荐下一个POI和下一个签入时间,并使用时间头作为时间建模的校准。此外,由于预测下一个POI类别比准确预测POI更容易,因此使用类别头来调节下一个POI预测。
3.4.3 Loss
使用交叉熵损失函数,最终损失为:
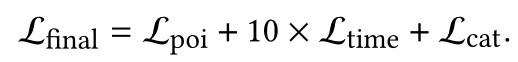
4. Experiments
4.1 Experimental Setup
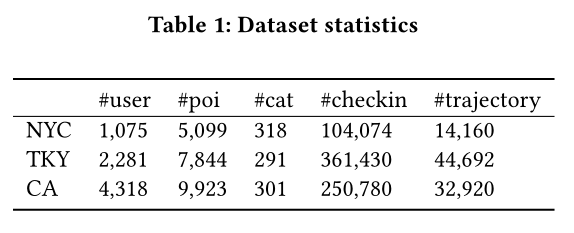
4.1.1 Datasets
4.1.2 Evaluation metrics
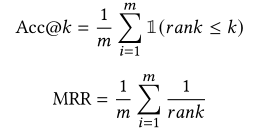
4.1.3 baselines
- MF
- FPMC
- LSTM
- PRME
- ST-RNN
- STGN
- STGCN
- PLSPL
- STAN
4.1.4 Experiment Settings
GCN模型有三个隐藏层,每个层分别有32、64、128个通道。转换注意模块将输入节点特征转换为128-dim矢量。对于变压器,我们堆叠了两个编码器层。变压器编码器层前馈网络尺寸为1024,多头注意模块采用两个注意头。此外,我们采用了学习率为1e-3,权值衰减率为5e-4的Adam优化器。Dropout在GCN模型和Transformer编码器中均启用,速率为0.3。另一个重要的参数是时间的权重我们设为10,以匹配POI损失和类别损失的规模。我们在三个数据集中使用相同的设置,每个模型运行200个周期,批次大小为20。
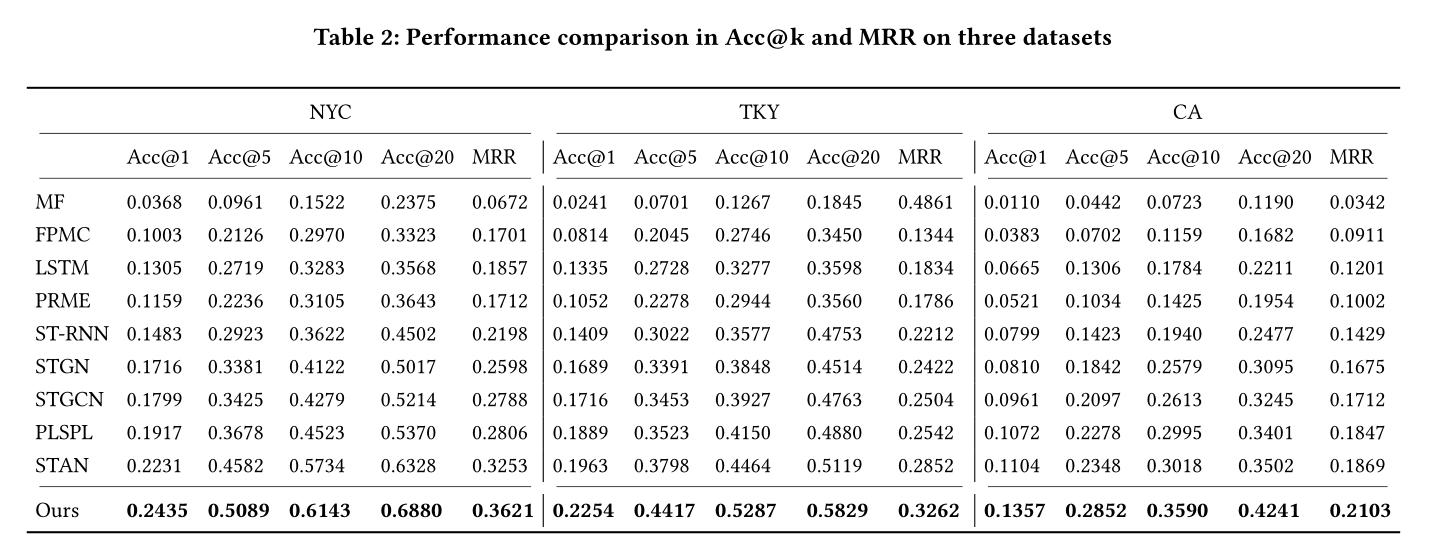
4.2 Results
4.3 Inspecting the Trajectory Flow Map
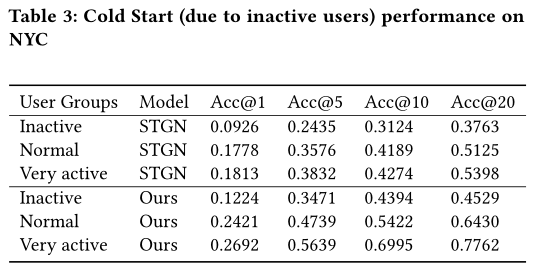
与其他方法相比,本文方法缓解了非活跃用户的冷启动问题和短轨迹。
4.3.1 Inactive users and active users
4.3.2 Short trajectories and long trajectories

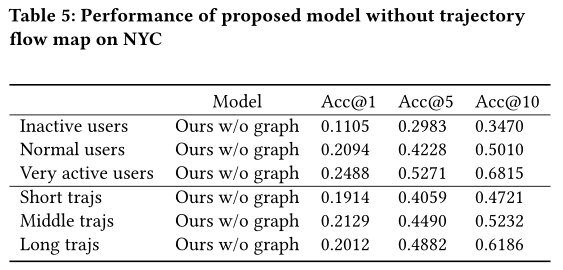
4.3.3 Removing trajectory flow map
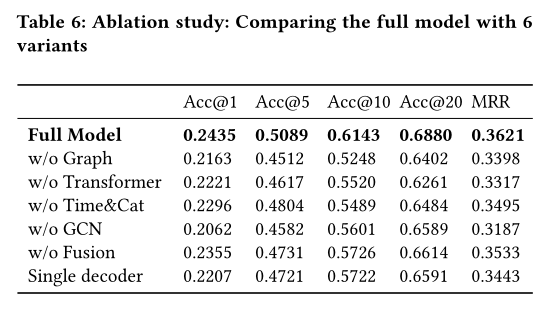
4.4 Ablation Study
5. CONCLUSION
本文提出了GETNext,是第一个在全局图结构上利用基于图的学习的POI推荐模型。引入了轨迹流图来捕捉用户的一般运动模式,以解决不活跃用户和短轨迹问题。我们定义了复杂的嵌入来编码时空上下文,其中包括用户poi和时间类别嵌入。我们将所有的嵌入都输入到一个Transformer模型中,它的输出通过转移注意力图得到进一步增强。通过在三个真实数据集上的一系列实验,证明了模型显著优于所有当前最先进的模型,并验证了模型的不同组件的好处。